

Consultores, Agências e Profissionais de Marketing Digital & SEO sabem, ou deveriam saber, o quão importante é um mecanismo de pesquisa indexar seu conteúdo. Diversas técnicas são aplicadas para fazer com que o site de seus clientes seja melhor rastreado pelo Google, e com isto ter a indexação total de suas páginas e conteúdo, através de ações on-page e off-page como a melhoria de conteúdo, geração de links, tags, meta-descrições, otimização de imagens, Robots.txt, etc.
Porém como digo em minhas aulas e palestras, o SEO On-Page pode ser dividido em duas partes: Conteúdo e Técnica. A parte de conteúdo trabalha com otimização de textos para palavras-chave, o tamanho da imagem, criação de links internos e externos. Mas a parte técnica é responsável pela criação do Sitemap XML, dos microformatos, Google AMP, Robots.txt e Meta Robots.
Os robots são mais conhecidos pela galera “old school” que vieram da área de desenvolvimento. Mas se você nunca ouviu falar de robots, não fique assustado. Este post é feito tanto para você que está aprendendo sobre robots.txt quanto para quem já entende e quer somente dar um up em suas visitas. Vamos lá?
O que é o Robot.txt?
Robot.txt é um arquivo de texto que é usado para instruir os robôs/spiders utilizados pelos mecanismos de buscas (como Google e Bing) a como rastrear e indexar as páginas de seu site. O arquivo robots.txt é colocado no diretório principal de seu site para que estes robôs possam acessar estas informações de forma imediata.
Para evitar que cada mecanismo de pesquisa defina regras específicas para seus crowlers, eles obedecem um padrão chamado REP – Robots Exclusion Protocol (Protocolo de Exclusão de Robots), criado em 1994 e sua última modificação foi em 2005.
Como os arquivos robots.txt fornecem aos bots de pesquisa instruções sobre como rastrear ou como não rastrear certas partes do site, saber como usar e configurar esses arquivos torna-se vital para qualquer profissional de SEO. Se um arquivo robots.txt estiver configurado incorretamente, ele pode causar vários erros de indexação. Então, toda vez que você iniciar uma nova campanha de SEO, verifique seu arquivo robots.txt com a ferramenta de teste de robots do GoogleRobot.txt.
SE TUDO ESTIVER CERTO, UM ARQUIVO ROBOTS.TXT ACELERARÁ O PROCESSO DE INDEXAÇÃO.
Usando Robots para “Esconder” seu Conteúdo
Os arquivos Robots.txt podem ser usados para excluir determinados diretórios da SERP de todos os mecanismos de pesquisa. Para isto, se usa a propriedade “disallow”.
Aqui estão algumas páginas que você deve ocultar usando um arquivo robots.txt:
• Páginas com conteúdo duplicado
• Páginas de paginação
• Páginas de agradecimento
• Páginas de Carrinho de Compras
• Páginas de Administração
• Chats
• Páginas com informações de conta
• Páginas dinâmicas de produtos e serviços (que variam muito)

Exemplo de exclusão de páginas com robots.txt
No entanto, não esqueça que qualquer arquivo robots.txt está disponível publicamente na internet. Para acessar um arquivo robots.txt, basta digitar:
www.meu-site.com.br/robots.txt
Como usar o Robots.txt
Os arquivos Robots.txt permitem uma vasta opção de configurações. Seu principal benefício, no entanto, é que eles permitem que os especialistas em SEO “permitam” (allow) ou “desaprovem” (disallow) várias páginas de uma vez sem ter que acessar o código de cada página, um por um.
Por exemplo, você pode bloquear todos os rastreadores de pesquisa com este comando:
User-agent: *
Disallow: /
Ou esconder a estrutura de seu site e categorias específicas:
User-agent: *
Disallow: /no-index/
Também podemos excluir diversas páginas da pesquisa. Basta esconder estas páginas dos crowlers com o comando “disallow”:

Removendo páginas da pesquisa com disallow no robots.txt
Uma das melhores coisas de se trabalhar com robots.txt é que ele permite priorizar certas páginas, categorias e até mesmo pedaços de código CSS e JS. Dê uma olhada no exemplo abaixo:
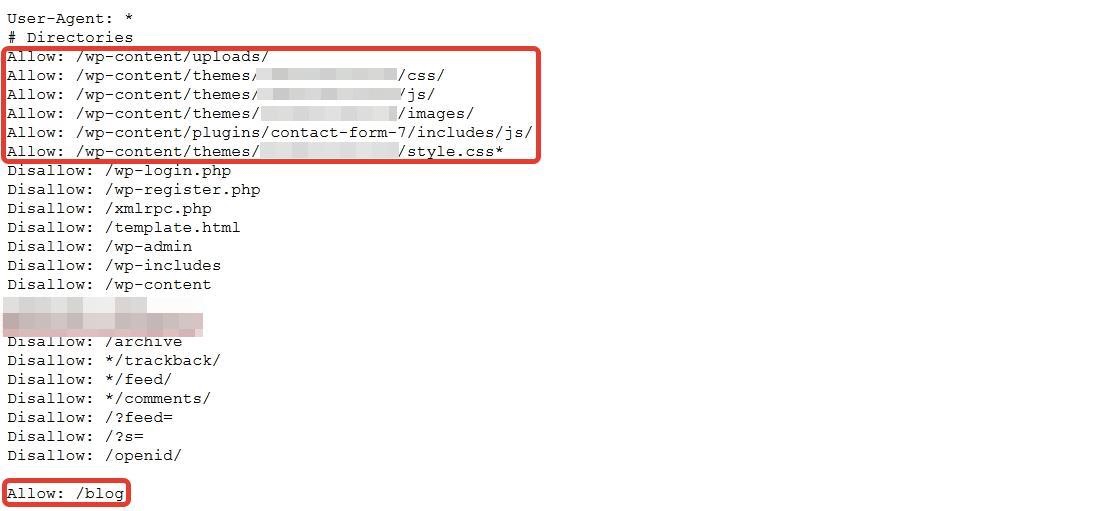
Priorizando páginas com allowed no robots.txt
No exemplo, não permitimos páginas WordPress e categorias específicas, mas arquivos de conteúdo wp, plugins JS, estilos CSS e blog estão permitidos. Esta abordagem garante que as aranhas rastreiem e indexem códigos e categorias úteis.
Principais comandos para o Robots.txt
Antes de terminar esta postagem, listarei os principais comandos e funções para que você possa configurar seu robots.txt em qualquer editor de texto:
Para indexar todo o conteúdo:
User-agent: *
Disallow:
ou
User-agent: *
Allow: /
Para não indexar todo o conteúdo
User-agent: *
Disallow: /
Para não indexar uma pasta específica
User-agent: *
Disallow: /pasta/
Para o Googlebot não indexar uma pasta, mas permitir a indexação de um arquivo desta pasta
User-agent: Googlebot
Disallow: /pasta1/
Allow: /pasta1/minha-pagina.html
Concluindo
O domínio dos robots.txt pode ser um fator muito importante para o sucesso ou fracasso de sua estratégia de SEO. Mas além dos arquivos textos, podemos trabalhar com os autorização dos spiders diretamente em nossas páginas com as meta tags robots. Mas este conteúdo fica para a próxima!






{kind=link}